torchpipe快速上手(30min体验版)
torchpipe是为工业界所准备的一个独立作用于底层加速库(如tensorrt,opencv,torchscript)以及 RPC(如thrift, gRPC)之间的多实例流水线并行库,助力使用者能在部署阶段节约更多的硬件资源,帮助产品应用落地。此教程主要针对初级用户,即对于加速相关的理论知识处于入门阶段,具有一定的 Python基础,能够阅读简单代码的用户。此内容主要包括使用torchpipe进行服务部署加速的使用方法、性能和效果差异对比等。本文档的完整代码见可详见resnet50_thrift。
目录
1. 背景与基础知识介绍
这几年深度学习发展迅猛,在图像、文本、语音等多个领域均取得了显著成果。目前已有一些模型加速技术通过计算、硬件优化等手段,提高深度学习模型推理速度,并在实际业务中取得不错成效。常见的有基于TensorRT、基于TVM加速等。本教程将以实际业务上线的过程中最简单的业务为例,介绍如何使用torchpipe完成线上服务部署的方法。整个服务仅有包含一个resnet50模型。整体服务链路流程如下所示:
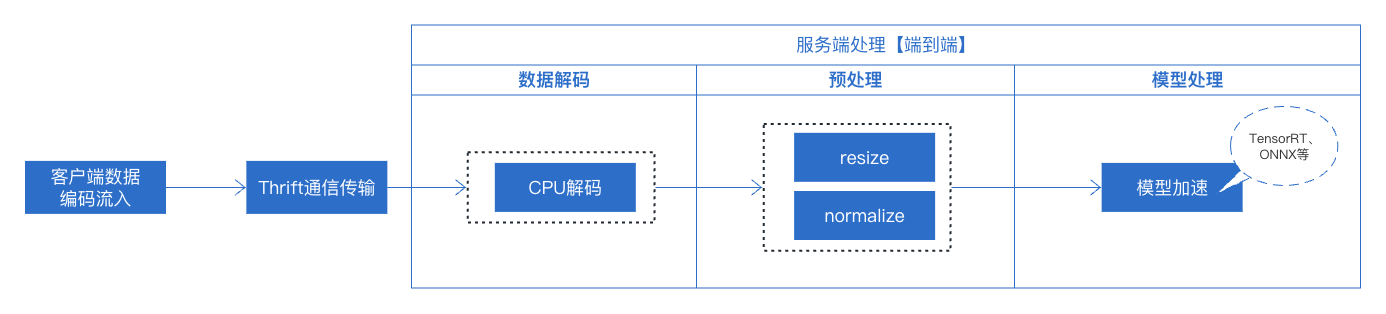
我们对模型部署中需要了解到的一些概念做一些简单的解释,希望对初次体验torchpipe的你有所帮助,可详见预备知识。
2. 环境安装与配置
具体安装步骤可详看安装, 我们提供了两种配置torchpipe环境的方法:
3. 从 TensorRT 进阶到 torchpipe
本节将从使用TensorRT加速方案出发,给出服务部署时的常规加速方案,然后在此方案的基础上,使用torchpipe来进一步完成整个服务的加速优化。
3.1 使用TensorRT加速方案
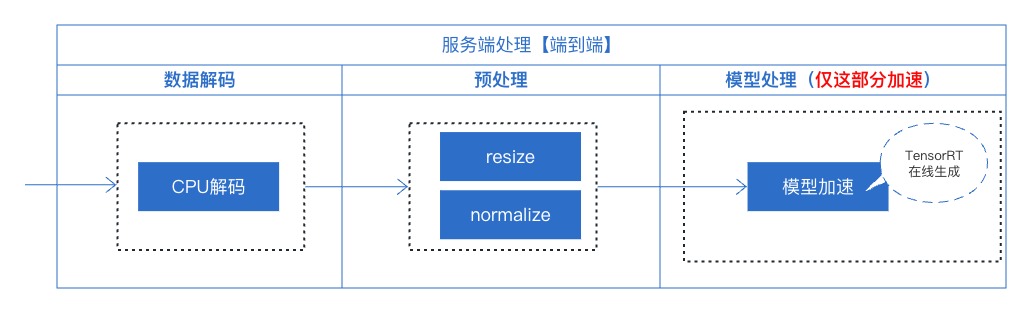
TensorRT是一个基于NVIDIA GPU的高性能深度学习推理引擎,可以通过优化计算和内存使用来显著加速模型的推理过程。然而,TensorRT仅支持对单个模型的优化和加速。因此采用TensoRT进行服务加速,仅对模型这部分进行了加速处理,因此,在此服务部署时,在数据解码和预处理中我们仍采用常规操作完成,这两部分均采用python完成,在模型上采用TensorRT进行在线成engine完成模型加速。
下面具体来看每一部分的操作:
1、数据解码部分: 这部分主要采用cpu数据解码来完成操作。
## 数据解码(CPU解码)
img = cv2.imdecode(np.asarray(bytearray(bin_list.data), dtype='uint8'), flags=cv2.IMREAD_COLOR)
2、预处理: 这部分主要采用pytorch的内置函数完成操作。
## 预处理
self.pre_trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]),])
img = self.precls_trans(cv2.resize(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), (224,224)))
3、模型TensorRT加速
input_shape = torch.ones((1, 3, 224, 224)).cuda()
self.classification_engine = torch2trt(resnet50, [input_shape],
fp16_mode=self.fp16,
max_batch_size=self.cls_trt_max_batchsize,
)
整体的线上服务部署代码见main_trt.py
因为TensorRT不是线程安全的,所以利用这种方法进行模型加速时,服务部署过程中需要加锁(with self.lock:)处理。
3.2 使用torchpipe的加速方案
从上述的流程中,我们可以清晰的看出来,在处理单模型加速的工作中,主要关注的是模型本身的加速,而忽略了服务中的其他因素,如数据解码、预处理操作等这些模型前处理操作会影响到服务的吞吐、时延。因此从这个角度出发,为达到最佳的吞吐量和时延,我们采用torchpipe来对整个服务进行优化,具体有:
- (1)多实例并行,采用多个模型实例并行执行推理任务。
- (2)batching,因为batchsize越大,单位硬件资源所完成的任务越多,因此送入模型前面会有一个凑batch的操作,以最大化单位硬件资源所完成的任务。
- (3)提供线程安全的前向接口
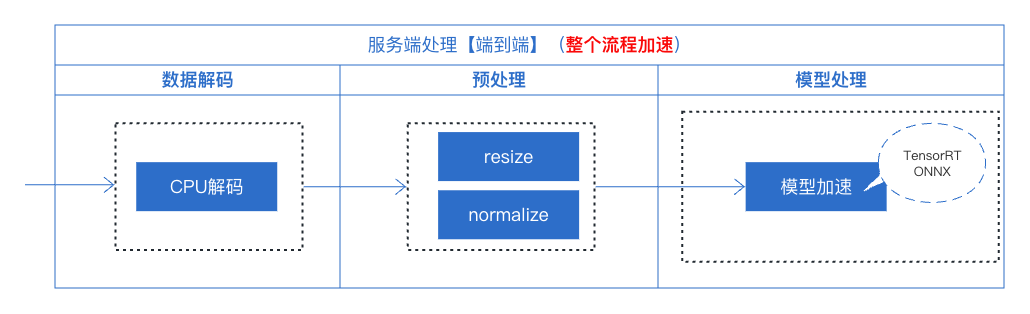
利用torchpipe对本服务部署进行调整,整体的线上服务部署代码见main_torchpipe.py,核心函数调整如下:
# ------- main -------
bin_data = {TASK_DATA_KEY:bin_list.data, "node_name":"cpu_decoder"}
config = torchpipe.parse_toml("resnet50.toml")
self.classification_engine = pipe(config)
self.classification_engine(bin_data)
if TASK_RESULT_KEY not in bin_data.keys():
print("error decode")
return results
else:
dis = self.softmax(bin_data[TASK_RESULT_KEY])
从上面的逻辑流程来看较原来的main函数的代码量更少了。其中关键就是toml文件中的内容,整个toml包括了3个节点:[cpu_decoder]、[cpu_posdecoder]、[resnet50],这三个节点串行进行,分别对应了3.1中的3个部分,如下所示:
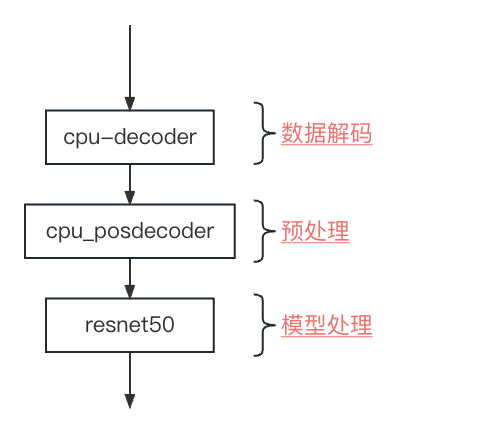
下面来看一下toml中具体每一个节点中都包含了哪些内容。
# Schedule'parameter
batching_timeout = 5 # 凑batch的超时时间
instance_num = 8 # 实例数目
precision = "fp16" #精度 目前也可以支持fp32、int8
## 数据解码
#
# 这里对应的3.1(1).cpu解码
# img = cv2.imdecode(img, flags=cv2.IMREAD_COLOR)
# 注意:
# 原先解码输出的是BRG的数据格式
# DecodeMat这个后端默认输出的也是BRG格式
# 因为是CPU解码,所以采用DecodeMat
# 每个节点完成后需要接上下一个节点的名称,否则默认最后一个节点
#
[cpu_decoder]
backend = "DecodeMat"
next = "cpu_posdecoder"
## 预处理resize、cvtColorMat操作
#
# 这里对应的3.1(2) 预处理
# precls_trans = transforms.Compose([transforms.ToTensor(), ])
# img = precls_trans(cv2.resize(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), (224,224)))
# 注意:
# 预处理原先的顺序是resize、cv2.COLOR_BGR2RGB、再归一化。
# 但归一化这一步目前已经融合在模型处理([resnet50]这个节点)中,因此在本节点中预处理过
# 程完成后输出的结果是与无归一化的预处理结果一致。
# 每个节点完成后需要接上下一个节点的名称,否则默认最后一个节点
#
[cpu_posdecoder]
backend = "Sequential[ResizeMat,cvtColorMat,Mat2Tensor,SyncTensor]"
### resize 操作的参数
resize_h = 224
resize_w = 224
### cvtColorMat输出的参数
color = "rgb"
next = "resnet50"
## 预处理中归一化 + 模型加速
#
# 这里对应的3.1(3) 模型tensorRT加速以及包括了3.1(2)中数据归一化操作。
# 注意:
# 与原先的在线生成engine的方法略有区别,这里需要将模型先转化成onnx格式。
# 转化方法见[torch转onnx]
#
[resnet50]
backend = "SyncTensor[TensorrtTensor]"
min = 1
max = 4
instance_num = 4
model = "/you/model/path/resnet50.onnx"
mean="123.675, 116.28, 103.53" # 255*"0.485, 0.456, 0.406"
std="58.395, 57.120, 57.375" # 255*"0.229, 0.224, 0.225"
# TensorrtTensor
"model::cache"="/you/model/path/resnet50.trt" # or resnet50.trt.encrypted
- 其他的一些具体的后端算子的具体用法和功能详见基础性后端、opencv后端、torch后端、日志中进行查询。
- 与原先的在线生成engine的方法略有区别,这里需要将模型先转化成onnx格式。转化方法见torch转onnx
- 在torchpipe中解决了TensorRT对象不是线程安全的问题,并经过了大量的实验测试认证,因此在服务运行中可以把锁给关闭,即
with self.lock:这句话注释(【3.1】线上服务部署使用核心代码main中)。
4 性能和效果对比
python test_tools.py --img_dir /your/testimg/path/ --port 8095 --request_client 10 --request_batch 1
测试具体代码见client_qps.py
采用相同的thrift的服务接口,测试机器3080,cpu 36核, 并发数10
- 从整个服务吞吐来看:
| 方法 | QPS |
|---|---|
| 纯TensorRT | 747.92 |
| 使用torchpipe | 2172.54 |
- 从整个服务响应时间来看:
| 方法 | TP50 | TP99 |
|---|---|---|
| 纯TensorRT | 26.74 | 35.24 |
| 使用torchpipe | 8.89 | 14.28 |
- 从整个服务资源利用率来看:
| 方法 | GPU利用率 | cpu利用率 | 内存利用率 |
|---|---|---|---|
| 纯TensorRT | 42-45% | 1473% | 3.8% |
| 使用torchpipe | 48-50% | 983.8% | 1.6% |